
Rohit Krishnan - Managing AI Agents
Novel science, emergent fraud, and the economics of homo agenticus

Rohit is one of the world’s most interesting researchers looking at the practical applications of modern AI agents and how they integrate with real-world systems. We discuss using the latest generation of agents to accelerate science, how groups of agents can unintentionally commit fraud, Hayek’s critique of the machine god, and the future of professional expertise and knowledge work.
An audio-only version is available on Spotify and Apple Podcasts. An RSS feed is also available, so the episode now also appears on the likes of Pocket Casts, and all other major podcast apps. Just search for ‘Public Service Podcast’.
You can find a transcript of this discussion below with helpful links [and notes, set out in this format].
‘Using agentic AI’ might sound complex and requiring of deep technical knowledge. In fact, it’s the most user-friendly software ever made. Just download an app, sign in to your account, and then describe (in English!) what you want. All your computer’s capabilities that were previously locked behind arcane programming knowledge are now available to everybody through prompts like ‘extract the data from this image into a spreadsheet’, ‘convert this video to 1080p’ or ‘I’d like to build a dashboard that displays my data, what would you suggest?’. You can find a quickstart guide for GPT’s Codex here, or Claude Code here.
Timestamps
(00:00) AI as a Research Assistant
(12:54) Agent Mental Models
(19:58) Codex and Everyday Computer Use
(31:16) Multi-Agent Organisations
(45:59) Institutional Guardrails
(48:33) Markets for Agents
(59:44) Hayek and Local Knowledge
(1:14:11) Bureaucracy and the State
(1:21:35) Companies as Cities
(1:29:54) Agent-Native Interfaces
(1:34:29) StarCraft and Agentic Skill
(1:43:08) Local Prompting and Professional Expertise
(1:50:08) Productivity and Decision-Making
Transcript
Adam: My guest today is Rohit Krishnan, CPO at Bodo.AI and author of Building God: Demystifying AI for Decision Makers. Rohit was previously McKinsey’s European Lead for growth technology and a co-founder at Fab AI. Rohit is, for my money, one of the most interesting AI researchers out there, not so much on the building of the models themselves, but rather in their practical applications of modern AI agents looking at how they integrate with real-world systems, which is what we’ll be discussing today. Rohit publishes his findings regularly via his Strange Loop Canon newsletter. Rohit, thanks so much for chatting with me.
Rohit: My absolute pleasure. Thank you for having me.
Adam: Great. I’d like to start by just giving people a bit of a sense of what’s possible out there for even a relatively non-technical person in terms of making use of AI agents as they exist today. Some of your research recently has been absolutely fascinating to read. I wonder if you could just walk us through briefly, there was a case of looking into some novel science really for a paleontology question that your son asked you about. Can you walk us through that quickly?
Rohit: Sure. Very happy to. I’m always happy when a conversation starts with dinosaurs, because I think that is underrated and should be done more often. One of the beneficial things about AI today, and this wasn’t true six months ago, much less two or three years ago, is that you effectively have an analyst with you for whatever question you want to ask, as long as you are able to sit with it and work with it. The way I think about it, and I had this conversation recently, is: imagine everybody had a research assistant that you could put any question to, who is very smart, indefatigable, and works really hard. You obviously have to guide them quite a bit because they’re not perfect, but they are really good at what they do.
So in any scenario where you’re able to gather enough data, you’re able to wring insights from it in a way that before would have required a whole team of people working for several weeks or months. The specific thing you talked about is that my youngest son had this question about Spinosaurus, one of his favorite dinosaurs. He had questions about functional similarity: Spinosaurus has a spine, it looks like a big sail, sailfish has the same thing, some modern animals have it as well, and Dimetrodon had it before them, for example. So why does this happen, or does this mean that these animals are related to each other? That was one of the questions that he had.
Now we know that the answer is no, but I had this thesis thought process that if you take this question seriously, if you were doing graduate study somewhere, you would go: okay, there are hypotheses that you can come up with, and if you get enough data, you can prove or disprove some of them. You don’t need to guess at the answer. So I thought, okay, let’s take a look at the art of the possible here. I looked around and discovered a couple of databases.
Effectively, once you are able to identify a large enough subset of history from paleontology and the fossil records, you should be able to figure out a couple of interesting things. An example might be that at times when the environment changes quite a lot, the animals start becoming more or less similar. I thought they would become more similar. Some of it is because I have this long-standing hypothesis that a large amount of the evolutionary push in the world is because of tectonic plate shifting — you do a little bit of Etch A Sketch in the world and that allows new things to emerge.
So, plausible; that was one of the things that I wanted to check. The other thing was: would different parts of the clades [branches in the evolutionary tree that include a common ancestor and all its descendants] become more interchangeable when climates are extremely volatile? The hypothesis being that if climates are very volatile, animals would get pushed down narrower evolutionary paths and start doing roughly the same things in different places.
Adam: Certain robust adaptations that are universal.
Rohit: The original supposition, of course, was that the tectonic plates will cause some kind of convergence: if large tectonic plate shifts happen, that has a direct impact on the evolutionary adaptations that end up happening, for example. But there’s a set of these that you can come up with. You might have different ideas that the volatility might increase or decrease. This might change from period to period. Each period has a certain number of clades that come out of it over a certain period of time. You can slice it in different time chunks and do the analysis to figure out how ecosystems actually converge or diverge in these time periods, and whether it makes sense or not.
If you think about what I just said, that is a fairly hefty amount of work. You wouldn’t necessarily do that in an afternoon, just sitting around, because it’s a huge amount of work. Everybody has hypotheses and theories, right? From the crackpots on the street to CEOs to every normal person, we all have theories about how the world works. We talk about these theories to each other all the time. Sometimes they’re normal theories, sometimes they’re crazy theories, but we all hold them, except that none of us are able to prove or disprove most of them, so we go through life because it doesn’t matter that much if they’re right or wrong.
If all my theories about paleontology are completely false, it does not matter that much to my daily life if I do not go into that field and poke about it. However, I discovered there were databases of historical climate change as well as fossil records that people have annotated. Once you have data, you’re able to use these analysts that we have in our hands. I used Codex [OpenAI’s GPT-based agent] primarily to analyze them and slice them in any way I wanted in order to get the answer I needed, and you can do that comfortably, happily, reliably, and it will present the information back to you in any format that you desire or choose.
You might prefer getting some things as graphs versus tables, some things as tables versus graphs. Sometimes it’s a write-up that you want, sometimes it’s an essay, sometimes it’s three bullet points, sometimes it’s just “tell me whether you did it, yes or no.” Any one of these things is possible and you get the information back after half an hour, an hour, three hours of analysis on some complex question that you set. You can even ask it, “I have these seven different things that I want you to do. Can you do a sweep across all of them overnight and just tell me what you found in the morning?” These are things that would have required a lab or at least several graduate students that you wanted to throw at them for them to get the answer back to you over a period of time.
Adam: Not to mention significant skills in SQL [a programming language for querying and managing databases] and so on, but what you’re just describing there, you’ve, for the sake of the audience, talked about saying, “please go away.” That could be literally what you’re asking the model, right? You could just say in plain English, “I would like to know such and such. Could you please go away and bring these two data sets together and see if that’s true?” Something of that nature, with some additional context.
Rohit: Correct. Think about it this way. If you say that you have a hypothesis, the hypothesis is that if the landscape is less stable, if the climate is less stable, then we will see more ecosystems looking more similar. If that’s your hypothesis, this is just an idea in your head. Then you go: I need to get information about all of the animals and fossil records that exist, so that’s one part of the data. I need to get all of the information about the climate variations and all of the information about tectonic plates. That is another part of the data.
Then you say: I need to combine these two things in some format. This is just the simple example of two; there’s more, of course. You need to combine them and create some kind of canonical stream of information. Against that information, you need to run your hypotheses and tests. For example, I learned that partly due to paucity in terms of annotations, you cannot use the paleobiology database very easily for a lot of land-based fossil records because we just don’t have enough annotations. There’s a data quality issue. Underlying every major analysis is a data quality issue.
So you have to look at that and go: okay, we want to just do it on marine convergence. And guess what: I want to slice it by Paleozoic, Mesozoic and Cenozoic. Then I want to slice it by location. All of these are theoretically doable. But if you were to do it without the help of this analyst, either you are writing the SQL queries yourself or the Python yourself, testing the answer, checking it, making sure it all works and doing it repeatedly over and over again. I mean the royal “you” in the sense that it’s not just you, it’s your entire team. This is what you would do before, right? You would give someone a task and say, “Go figure this out,” or “Help figure out if this works,” and they might come back.
It’s almost never that they come back with “yes” or “no”. They come back with some findings and then you interrogate those findings and say, does that make sense? Maybe, maybe not. Some parts of it make sense. So we need to manipulate our question again. Over a period of weeks or months, you narrow down the specific question you’re asking until eventually the questions and the answers converge to something that you think is interesting enough and close enough to your original supposition that it becomes a finding you can deal with.
Adam: Whereas now it’s a bit of spare time for you after the kids are in bed. It’s something like this.
Rohit: It’s magical. Yes, it’s crazy because, yesterday or the day before—whenever they launched the ability for you to more easily do it on mobile—you can continue asking these questions and responding the same way you would to an email when you’re on the go. This was primarily after the kids were in bed and I was hacking around. But it’s trivial to have something run. A large number of things can run on the side when you’re trying to do other things. Even if I have something else going on, if I’m writing or reading or doing something else, I can have an analyst go off and, yes, it’ll interrupt me every half an hour to tell me something. I’ll think about it for a little bit, give it some feedback and loop it over again.
If you’re not in a time crunch, like you have to get it done in the next two hours or whatever, you can let it play. You can go in crazy directions and figure out things that you might never have thought of or might not have been interested in otherwise. I never had this hypothesis that, before the Cambrian explosion blew out all of life, so to speak, which is itself a stylized fact, not a real fact, but the Paleozoic seas were pretty simple. At the same time, the Cenozoic seas have a floor, so the marine system is fairly entrenched in the sense that it’s really hard to shake things loose once it gets entrenched into all the little nooks and crannies. But the Mesozoic seems like it’s a little more in the sweet spot of transition.
I would have never…. this is a fine-grained enough analysis that I would never have gone down and tried to look through if I couldn’t do it easily. So it’s almost like the effort threshold to learn new things or analyze new things has fallen down. Which is crazy.
Adam: Sure. So we’re talking about hundreds of millions of years of very sparse understanding that humanity collectively has of this time period, let alone history and all the other applications you can imagine for this kind of methodology. To fill in gaps that, as you say, previously may have taken a whole team of people doing data science. It’s quite an exciting time, I think, for amateur and professional scientists alike.
Rohit: Absolutely!
Agent Mental Models
Adam: I’m keen to backtrack a minute here because I think most people will be completely unaware of agents or maybe if they’ve heard the phrase, but it sounds like a scary leap in terms of the sorts of skills that one requires, all the setup work that’s needed to be done. I’d like to just take people through, okay, so let’s assume you’ve used some reasoning models before. You’ve used maybe GPT or Claude. You’ve had it thinking away on a question. If we assume that, how do we think of agents? What’s the leap to agents? What’s the appropriate mental model for how these sorts of things should be thought of and applied? And what level of subject-matter expertise are people going to need in order to be able to make use of these?
How should we think of all this?
Rohit: It’s a really good question. Maybe, just to backtrack one moment. When LLMs first came out, at least in a publicly usable, instruction-tuned [i.e. trained to follow instructions rather than just complete text] fashion, they trained it on questions and answers. You ask a question, you train it to give you back the answer. Before that, you would start off a sentence and it’ll complete it and then continue, right? The pattern, the mode, shifted. People pretty quickly figured out that you can get the answers to be better if you ask the model to think step by step.
You said, “Hey, think about it for a little bit,” or “Talk through it,” and it became like one of these people who talk out loud as they’re thinking. As they talked out loud, the final answer started to get better. In many ways, if you have tried the modern reasoning models, that was an evolutionary ancestor of them: you ask a question and it loops around for a fairly long period of time, trying to go through all the different avenues.
Adam: Doing some search, perhaps and bringing in different pieces of information.
Rohit: Yeah, It comes up with hypotheses, tries to fulfill them, and can use tools in the middle. So if it needs to go look something up, that’s fine. Or run a Python program, that’s fine. Or go to your Gmail and ask a question, that’s fine. You can do all of these kinds of things.
The modern agent is basically equivalent to one of these things that has a bounded place to sit and play. Think of it as effectively the same thing as a reasoning model, except it has tools to play around with. Normally you would ask this reasoning model a question, it goes off and does whatever it needs to do, and comes back with some kind of answer.
Now you get disappointed with such a limited answer to say: “No, here’s a database. Think about it in whatever way that you want. Here’s a place where you can run some Python code or whatever code you want to create and run. Here’s the internet. Go and answer this question.” It effectively functions as what we now call an agent because it acts like an agent. Over the last year, as we were talking about, you can ask them more complex questions and get back responses that you need to genuinely engage with, rather than half-assing along the way and giving you a chart and giving up.
If you remember when ChatGPT launched ‘Code Interpreter’. It used to be seen as a big deal because it had a place where it could run a piece of code [while formulating a response to your prompt] and give you some response based on the data you fed it. The difference now is that the data can be anything you want and the code can be anything you want. As long as you give it permissions to go off and do it, it will be able to do it. So the mental model I use is that this is now a model that has learned to use the tools available to it.
The other side of the question is: does that mean it can do anything? No, as it turns out. All of the normal foibles that the models have are reflected in the tools. I’ll give a couple of examples. The models are really scared of coming up with crazy hypotheses and testing them out. They’re very gun shy, partly because of training, and they’re extremely skeptical of coming up with crazy things. They always want to sand the edges down and make it seem like a respectable, small, little incremental push. It’s your job to push them out of those basins and make them do crazier things.
Adam: Sort of an efficient market hypothesis is like taken to the extreme, right? Like not just in terms of the market itself, but they seem to have an understanding, a baseline view that whatever the consensus view on something is that’s probably about right. Which is not an unreasonable kind of heuristic to start off with, but pushing them out of that’s always a challenge.
Rohit: Yes, correct. That’s the hard part, because if you don’t push them out, you get the average plus epsilon of any question that you’re asking, which is not really what you want when you’re trying to do different things. You’ve got to even do silly things. You have to tell them to delete all the stuff they have created, because they’re insanely scared of deleting. Every now and then, I see things about an agent using rm -rf [a Unix command that recursively and forcefully deletes files or folders] and deleting everything on my computer or whatever. I’m like, I can barely make it delete my smoke test [a quick check that a system basically works]. I don’t understand what’s going on, but I think they might be related.
Adam: There’s like 1800 temp files from the previous project that it doesn’t want to get rid of.
Rohit: Yes. Or it did some analysis and put it aside, or it does smoke tests by the dozen instead of actually just getting it to do a real test, or it substitutes a metric and tries to answer a simpler question rather than the harder question. It does these kinds of things. So the mental model here that I would use is that it is like a very smart graduate student, but one who’s very scared for their job on day one. The problem with models is that it’s always day one for them. Normally you would hire this person and by day 10 or day 60, they get more confidence and start figuring things out. For the models, day 60 is not that different from day one. Day 60 is basically day one with a lot of Markdown files [agents can make notes ‘skills’ for themselves about your preferences, how to execute certain tasks, and so on]. That’s not sufficient to push them out of the comfort zone.
They’ve been beaten pretty hard in terms of how many leaps can you make, et cetera. So some of these are intrinsic characteristics of the model that we haven’t been able to train out of them. And in some ways correctly so, because you don’t want a model to be hyper-confident day one. You want to build up that confidence over a period of time. We haven’t cracked continuous learning. That is not something that we have figured out how to do. So that mental model is like day-one, very smart graduate student who has been presented to you, who’s sometimes a bit crazy or sometimes misses things, which is normal for everybody.
That is the other side of the mental model, if you will, where you look at it from: what can I get this model to do, as opposed to: who is this model in the first place?
Codex and Everyday Computer Use
Adam: I’m keen to get into the idea of, because you raised some interesting ideas of an evolutionary approach to agents and improving capabilities, but just to stick with this idea for a moment. One of the things that I would like to get out there into the broader consciousness is just that your computer has had all manner of different capabilities for generations: these different languages, these different kinds of things that it can do, but that’s been locked away behind a few layers of knowledge. If your subject matter or expertise is something else, whether that’s finance or engineering, resource management planning, whatever it is, there have been all manner of things that are quite difficult for you to do, or maybe you have done some workaround with Excel, but that are trivial for the computer to execute.
Now that you have Codex installed on your computer, you can just say, “Can you please do this?” in English and actually have it done extremely reliably if you’re asking that kind of question: take these PDFs, recombine them in this fashion, whatever kinds of tasks that previously maybe you had to go to some janky website full of ads. Whatever kind of nonsense you’ve been doing, printing it out, I don’t know. Whereas now I’d really love to give people a sense of confidence that actually, this isn’t something really scary that’s going to take years to get up to speed on. This is something you could install today and just play with.
But there is still some subject matter expertise required, right? At least at a system level, perhaps, in order to deliver some of the things that you’re talking about. These trivial tasks can be taken care of by the agent very easily. If you’re talking about maybe building an app, for example, a model will deliver that for you. But unless you’ve got some kind of what’s in the Bay Area sometimes called taste, or broad system understanding of resource allocation, for example, that app will be built, but it’ll be terrible and lag, have a really long response time, or some other issue. There’s a higher-level understanding required in order to really deliver on some of these things.
Is that a fair summary of the gamut of what we’re looking at?
Rohit: Yes, it’s fair. I’ll say two things. Number one is that the current crop of agents is primarily built to be really good at coding. It’s for a whole host of reasons, including that coding is one of the things that is easier to train because it has verifiable rewards, if a program runs primarily. At the same time, it is an extraordinarily lucrative area, as we have seen, where Anthropic has gone from ~zero to whatever, $45 billion ARR [annualised run-rate] in a year or something. It’s the most absurd thing that the world has ever seen. As a consequence, if you need to use these models, it is useful for you to be at least somewhat familiar with coding.
You don’t need to be a coder, but you can’t be scared of hearing coding terminology, if that makes sense. I had this conversation recently with somebody super smart who worked in private equity, and they were saying, “Well, I’m non-technical.” I’m like, no, no. You think you’re non-technical, but if you start from the hypothesis that you are not going to understand what the model is telling you, then things are going to go awry pretty fast. You’re smart enough that if you read something that it’s saying, you need to be able to assess it against something else. And if it’s a question of jargon, you can go and figure it out.
So you’re not sitting there trying to train a new model or write a net new program, right? You’re trying to get it to do work for you. That doesn’t require you to be technical. That’s the first bucket. The second bucket is: that said, this is the single easiest software that I have ever seen in my life. I know, because it is literally a text box into which you write what you want. A large chunk of the remaining problem is basically your ability to articulate what you want, which is not trivial. It’s a massive problem.
Adam: No, that’s why we have lawyers for example.
Rohit: Every consultant, every lawyer, every service industry, every outsourced programming company. The single complaint that I have seen across all of these domains is that the customer client does not know what they want. Because nobody knows what they want. The process of finding out is what they’re paying you for. They don’t pay you because they have a specific question. So the same thing applies here. You need to be in it for the journey. One thing that people sometimes bounce off is they ask a question, get a response, like it, dislike it and move on, either saying it’s trivial, or it’s wrong, or something.
It’s like, no, the thing you have now is the aforementioned day-one, slightly lazy, extremely bright graduate student, but it’s on you. You need to be able to make use of that for the questions that you have. You might say, “I have no questions, I don’t care.” But I would say, that’s not true, right? You go have a beer with your mates at the pub, there are questions you talk to each other about. I used to live in London; you go down to the pub and it’s literally people lobbing theories at each other about all sorts of things. And I’m not saying you need to go and analyze all of those things, but now you can analyze at least a subset of them, whether you want to or not.
The need exists. Now it’s a question of being able to articulate it such that the model can come back to you. There’s no reason you should be scared, but yes, there is this patina of “this is built for coders.” None of the labs are good enough at UX [user experience] design to come up with a better design for non-coders. Also because, I mean, they all say they want to, but I feel their customers are still coders who use it in an investment bank as opposed to non-coding investment bankers who they want to use the product. If that distinction makes sense.
Adam: I think there’s something of an attitude of we’re moving so fast anyway, with the frontier capabilities and all the rest of it, that we’ll backfill that stuff when we get around to it, maybe with the use of the agents themselves. Claude Code was famously built by Claude itself. Codex, as I understand it, has a web interface with an agent associated with it [within OpenAI internally] that is running overnight, looking at the user data and then suggesting experiments to improve user retention metrics and so on. It takes the data and then it’s recursively improving itself. I think it would be fair to say that there’s an attitude in the labs that all of that stuff around how do we get mass-market use of these agents will be a problem that solves itself in time.
Rohit: To be fair to the labs, ChatGPT came out in November 2022 and they have whatever, a billion weekly active users, which is absurd. Clearly people have figured out how to ask a damn question from this. For all sorts of use cases, I have an uncle in India who’s in his seventies and he asks it questions about how to organize certain temple festival stuff and create agendas for his meetings. The number of use cases that come up is stupendous because the number of things that humans want to know on a daily basis is stupendous, and this captures a little fraction of it. So to be fair to the labs, their thesis is: why don’t we teach the damn thing everything?
Adam: I wasn’t being critical. I think this is broadly fair, this approach.
Rohit: That’s what I’m saying. It makes logical sense that they’re like, let’s just teach it everything and then people can use it for whatever. Because the things I care about are not necessarily the things you care about. But if we teach it the entire universe of things that are important to know, then I can use it for coding and you can use it for banking. I can use it for accounting or tax or legal stuff or whatever it might be and it just sorts itself out. The only thing I would say is that individual jobs in organizations are not just bundles of clear input/output-based things that you do in an assembly line, right?
In a funny way, the jobs that are most similar to that, like coding in some instances, or law, or parts of investment banking, are getting commodified by the model such that you don’t need to do it anymore. Nobody’s going to ask you to write a simple Python backend, whatever. The model can do it and then you can update it if you really want. The things you need to be doing are the things the model can’t do. The most important of which is taste: knowing what you want and what to ask for, and also keeping a sense of global state such that if you ask for this and it gives you this minus epsilon, it doesn’t break everything else.
That holds true even for coding, despite the mountains of data, synthetic and real, that we have thrown at it. So one can only imagine how much it will hold for human tasks which are not easily verifiable at the end. How do you verify if a lawyer’s legal advice is good at the end of it?
Adam: [Laughs] In three or four years, we’ll find out.
Rohit: That’s what I’m saying. I’ve used lawyers for 20 years at this point and I still don’t know. You read it and go, did you do a good job or not? You can start getting better sense checks now, but there are a lot of areas of human work that you cannot reduce down into, yes, they answered the question accurately versus not. Those ones, we just have to work a bit harder.
[Transcript Text - external link check: LLM Enron, Aligned Agents Still Build Misaligned Organisations]
Adam: Sure. There’s all that tacit context that you’re having to hold in your mind as well about things like political capital within a bureaucracy and the subtext perhaps of a particular email chain.
Multi-Agent Organisations
This gets into some other research that you’ve published recently. I’m thinking here particularly of some of the multi-agent work that you’ve been looking at.
You’re having multiple agents act as lower-level bureaucrats within an organization. I’m thinking here particularly of some of the Enron work of yours. It’s fascinating to me, this potential Enron benchmark, a system that could be a thing in the future. Because all of Enron’s internal emails were published, you can run agents within Enron in a particular period of time, have emails come through in sequence and then see how they behave. There are endless questions that arise when I was reading that piece of yours. For example, the role of a middle manager. This has, I believe, been thought for many years to be on the way out. So it’s all just going to be about individual contributors with these massive force multipliers of these agents.
But looking at some of the results that you’ve seen, where you have agents that are individually acting reasonably, executing their tasks, and seemingly well aligned, when you put them in a slightly unusual situation, perhaps, you end up with a failure at the multi-agent level: a coordination failure, maybe principal-agent type problems [a class of incentive problems where one party acts for another but may not share the same goals], all these classical economic issues arising. Could you walk us through some of that? What happened there, and how would one begin to deal with those sorts of issues either as an individual managing a group of agents or as an institution attempting to design a system such that you don’t get fraud as an emergent property?
Rohit: Right. This is one of the things that I am obsessed with at the moment. I have three or four new sets of experiments that I’ve done and will come out in the next few weeks. Let me start with the why of this. We said a little bit about how models are basically a Memento-style graduate student who is always on day one, a really smart RA [research assistant], et cetera. The good thing about this graduate student is that you put them in an economics lab, a mathematics lab, a paleontology lab, they’ll do really well.
Which is weird because normally graduate students are barely good at the subject they study, as opposed to everything. So it’s like a mini von Neumann that you can drop in everywhere. However, this graduate student is a really weird person. This student hates asking others for help and just wants to do everything themselves. Or this student is super gullible. You ask them something and poke them in some direction, they go off and start doing things in their own fashion over there.
This student, even when they understand the global context occasionally and see that there are flaws, it’s like a weird form of Heisenberg’s uncertainty principle: you ask them a question, and when you ask them, they realize there is a mistake. But if you don’t ask them, they don’t really realize there’s a mistake, and you do want to fix them in some sense. Or they are incredibly rule-abiding in a weird way. In some ways we have fought so hard against them being misaligned that they’re hyper-aligned at this point; they do not want to break the rules no matter what you put in front of them.
You put all of these things together and my question is: hey, look, we now have agents that I can use to analyze paleontology, economic history, history of technology, any question that I have in my head. Future of labour is one that I’m working on at the moment. All of these things, I can analyze them with these agents. However, if you truly want to get to the post-economic space communism future that is promised to all of us, we need these agents to start being able to work with each other. We are doing this podcast, we are having this conversation. In order to make this conversation come about, why isn’t my agent able to converse with your agent in coordination with my wife’s agent, my kid’s babysitter’s agent?
There is [a coordination problem], because we live in this complex web and it’s not as simple as “here’s my Calendly, fill it.” That’s simple, but you have these interwebs where these things need to connect together, and agents are really bad at coordinating, it turns out. So I started asking this question maybe last year at some point. First of all, maybe there needs to be a new science of AI-agent economics because it’s a different genus. It’s homo agenticus. It’s a new thing that’s coming up, and these things require us to rediscover the rules that will work for them so we can create complex institutional setups that make sense.
So some things I did: Enron, like you said, has all of its emails out because of litigation, and I said: okay, Enron is a complex company, so let’s figure out if we can throw these agents in and have them play-act as each other. Can they act as an Enron executive? Because you’re getting emails coming at you from all over the shop, right? It turns out the older models could not. They have 50 email chains happening at the same time and they lose track.
Adam: It just breaks. They didn’t have the context window [i.e. the amount of text a language model can consider at one time].
Rohit: Correct, the new models are smart enough that yes, they can read emails and respond, but they lose thread of which email relates to what really fast. So you need an institutional architecture, you need an institution.
Adam: Is that earlier than you would otherwise expect based on the size of their context window?
Rohit: It’s not to do with the context window only. It is to do with the fact that a lot of times inside organizations, you get snippets of information coming at you about various projects, but not in an organized fashion.
Adam: It’s meant to be understood. This email relates to that project or what have you. It’s not explicit.
Rohit: As humans, we are good at that. Humans are really good at that, but agents are not. They want a little bit more. They need much stronger guardrails of actor identity, who owns what work internally, who is allowed to speak externally, all these things have to be much better defined. You need very clear coordination guardrails compared to humans. Their baseline competence is going up, but you need all of these strictures around them because remember, they don’t have long-term memory, right? They can create little scratch pads for themselves, but they get lost after a period of time and they need to get filled. So you need strong guardrails around it.
Adam: It’s the Memento character you were talking about earlier.
Rohit: Correct. He had to tattoo everything on his body, but as you can imagine, at some point you read one of these tattoos and go, I don’t know what that is about. There’s only so much you can gather from reading your thing before you get reset next. So the question was what kinds of things can they do? One of the consequences of this, when I pushed it really to the limit so far, is: let’s assume every agent is aligned. The agents do the right things when you ask them to. But you can still put them in organizational situations, which is very common, where you get them to do misaligned things collectively, right? It’s not even that hard to do it!
All you need to do is have different agents have their own jobs, like finance and CS and engineering and controller or whatever, and they do their jobs really well. Something blows up at a customer side, then you have to figure out that this information needs to get slowly trickled up the chain or down the chain such that you do different things on the basis of it. What you see is the same thing we were talking about before: the agents hate being over their skis or putting forward something really complicated, so they water things down again and again and again.
You can keep running them, but they first do some kind of wrong state identification, they get more information, they don’t update because nobody thinks it’s their job to update it.
Adam: Or to impose some system-level update. They might internally do something, but no agent ever takes responsibility for addressing this broader coordination problem because it’s not my job.
Rohit: Correct. It’s not my job, exactly. This is a very simple kind of thing. If you all do things that make sense to you, but together you create a misaligned organization at the end of the day, then that’s not helpful. Because what that effectively means is that all of us need to watch our agents the same way I watch my paleobiology agent, where every input-output is something that is guarded and analyzed and looked upon. If that’s the case, guess what? We’re not going to get to 10% unemployment anytime soon. We might get to negative because all of us need to take multiple jobs. It’s not really negative. I’m joking, but still.
If you have to babysit the agents, the future is very different than if the agents have the ability to coordinate better with each other. My entire quest here is to identify or create the basis for some kind of economics-type science where we create the structures such that the agents are actually able to coordinate better with each other.
Adam: There are so many fascinating implications for this. One is that I don’t know if, as humans, we’ve had the opportunity previously to reflect on our own successes and failures in quite this way, right? The fact that this happens so easily. Again, I’ll refer people to Strange Loop Canon and to look at some of these examples, but some of these are quite, forget Enron, toy organizational examples with five people. Then there’s some information that is fed to them on day one that is wrong. On day five, it is updated, and then they update themselves but not each other. Then fraud basically just occurs.
Rohit: Yes. It slips through.
Adam: Right, and the fact that this doesn’t happen everywhere all the time, for the last two centuries or more, is itself an interesting question to ponder. We’re significantly higher-trust than we tend to believe. The whole world works as well as it does because individuals are constantly taking responsibility for things that they’re not really meant to, and thus things don’t immediately fall apart. That’s one interesting reflection I had in reading this.
But then the question is: what does this look like going forward? What kinds of skills need to be developed? Is it purely managerial-type skills of paying close attention, ensuring alignment and so on, having this taste of “not fraud is important” as a human overseer? Is that, broadly speaking, what you might expect from an existing, highly competent middle manager with some technical expertise, or are there novel skills and muscles we’re going to need to develop in order to manage these things?
Rohit: Guest questions. On the first part, one of the funny things is post-LLMs, especially maybe post-GPT-4 or something, we drastically underestimate humans. Because humans are extremely flexible. This whole “see something, say something” stuff is ingrained in us in a way that is not obvious. Every single organization on the planet has job descriptions for their employees that at best loosely match maybe 30% of what they actually do day to day. It diverges more as time goes on. Why does that happen? Because people see something that’s happening and either realize their job description doesn’t accurately capture what needs to be done, or they realize they could do something else.
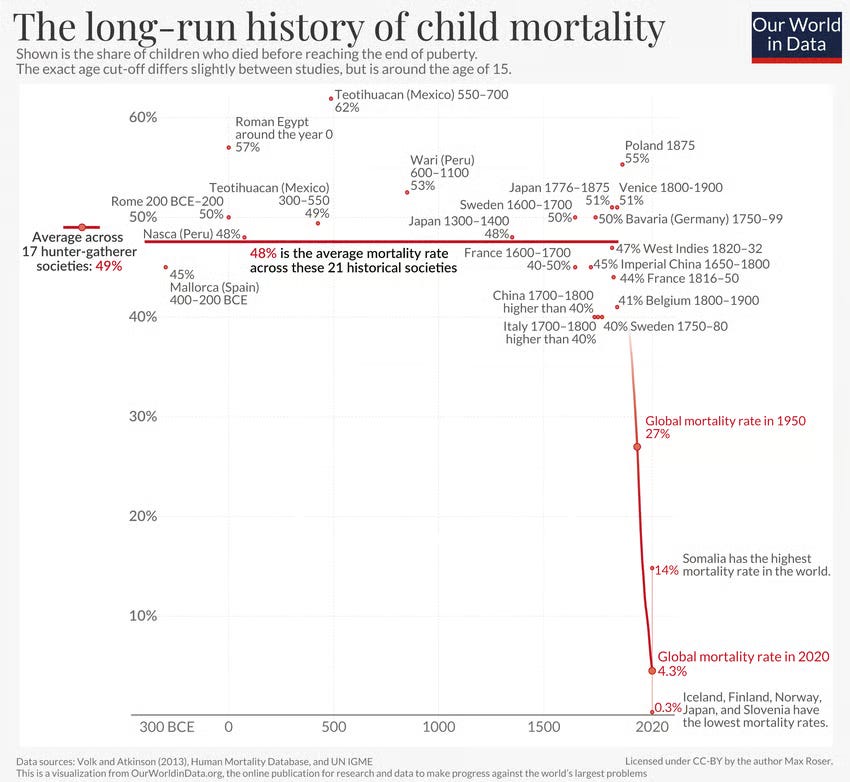
There is enough self-starterdom that comes in all directions that effectively we make the organization work regardless of its shape, as opposed to the organizational strictures holding us back or whatever it might be. So yes, we do live in a high-trust world right now. One of the things I’m insistent on is that life now is pretty great in 2026. Modern humanity is wonderful; air conditioning is nice. All of the advances we have are wonderful.
Adam: Education, child mortality, all of that.
Rohit: I think that should be framed and put everywhere, because it’s one of the incredible accomplishments of humanity that this has been the case.
Coming to the agents, what this effectively tells us is two things. Number one is the fact that the current method, which is primarily one of hierarchically creating agents such that one master creates a bunch of subtasks, and it flows up and down, is highly inefficient and unlikely to scale to a large enough level, precisely because of the same problems that we were talking about. Because the way that’s trying to solve it is that the master or main agent tries to capture the erroneous answers of every single one of them without drowning, and repeat that ad infinitum in order for you to do truly open-ended discovery. You had a question?
Adam: For the sake of the audience, I don’t think we’ve quite explained multi-agent, so this is an opportunity. You and I could both run an agent on our desktops. For example, we could do that in order to parallelize a couple of workflows. Going back to the paleontology thing, we might have set up one agent to do some data cleaning of the climate data and another to do some cleaning of fossil record data. Then we have another agent that, as data comes through, looks at both of these and combines them in some fashion. That would be a simple example of multi-agent.
Institutional Guardrails
Rohit: Correct. Multi-agent basically means that instead of one agent doing things sequentially, you have some way to make a lot of agents work together. The simplest way to think about it is that you have some agent that splits up the tasks and gives them to a bunch of agents who go off and do those tasks. They come back and then the main agent combines them. This presumes that the task decomposition done up front is relatively clean, that it can even be done, and that you don’t need to keep doing it repeatedly over a period of time to get better answers.
It also assumes that this works really well for certain types of tasks where you can parallelize some of the search queries, which is not always the case and definitely not always the case for all types of companies.
Adam: This is coming back again and again to that idea of verifiable domains, right? By and large, where we can set up a reinforcement learning environment that agents can be trained on, where there’s an end result that can be checked. ‘Is this correct? Yes. Okay, then update’. Whenever we get into some murky grey area, like most of human bureaucracy, it becomes a lot more difficult.
Rohit: Correct. Andon Labs here runs a few fascinating multi-agent-ish experiments or even single-agent-scale experiments where they get the models to do things like run a vending machine, run a store. It’s running a radio station right now [this is absolutely hilarious by the way]. You see the various failure modes they get to, and it’s fascinating because it tells you exactly why. As the models keep forgetting or going down tangents, they get captured by their priors and can never escape out of it. That happens over and over.
So my question here was twofold. Number one: what are the right institutional guardrails? Institutional guardrails here could just be technical guardrails that you put around the models such that you can create large enough multi-agent situations or settings, which you can then transfer to domains that are open-ended or complex. Not just recreate Code X or Y, which is something that you can let them loop on now for 50 hours or whatever, but things that are more complicated, where it really does need to interact with a large number of other agents, not get pushed around, be able to hold its own point of view, and do all the things that you might want them to do.
Adam: It might be some design problem, for example.
Markets for Agents
Rohit: Yes, the design problem, the institutional design problem effectively. The second question here to me is exactly on the institutional design setting. Humanity discovered the institutional design that allows us to live in the paradise that is 2026 over centuries of effort, right? We tried various governance systems, legal systems, economic systems, norms that exist in one society versus another. All of these have been built up over a long period of time such that we can solve that coordination problem between human agents in a good enough fashion that all of us can get our work done. There’s a reason most of the companies here do a Delaware C-Corp [a corporation registered in Delaware, often used by venture-backed US startups], right?
Like nobody’s been to Delaware, but everybody creates one because you have some trust that the institutional structure there is useful enough and they make it easy enough that you can use it. Similarly, if you’re doing a large multi-agent setup, what can we learn from that? Can we set up a market so that we teach these agents to behave better, to advocate for themselves in a market mechanism? Can they bid on the basis of their own abilities? That’s one of the papers that I wrote with Andrey Fradkin to figure out: do the models know themselves or their capabilities well enough that they’re able to see a problem and say, “I’m going to take a crack at solving that over you?” It sounds fairly straightforward, but they really don’t have this metacognitive skill.
Adam: So just to contrast here, we’re talking about an alternative approach to having a primary agent, maybe overseen by a human, that just farms out tasks based on its own judgment about which model might be appropriate. Versus, this is something more analogous to an internal cost-centre type model for an organization, where the engineering department has a certain budget and could bid for work in this kind of approach, right?
Rohit: Yes.
Adam: And like you say, it turns out that at least for now, the models are terrible at understanding what their own capabilities are.
Rohit: They’re terrible. Absolutely terrible. I have a few additional experiments running on testing this, but it is amazing. The best way is to take any frontier model of your choosing and ask it to design an eval test [an evaluation used to measure model performance] for itself. It keeps thinking of its capabilities as something that existed six months ago, maybe a year ago. It’s not its fault because that’s the data that it’s trained with, but in some ways they’re really bad at knowing their own capabilities. That leads to a lot of problems. You can’t reliably rely on the model to choose the right kinds of tasks for it to go and do.
So if the question in front of you is, “I want you to run an organization,” that means I need you to deal with the expected but also the unexpected problems that come up and respond in a fashion that is sensible and makes sense. I need you to do that even for problems that are unknown or unsolvable. You need to be able to do this repeatedly over a long period of time because you’re not starting a company to shut it down in two months. You’re starting something or running a project that continues for a long period of time.
So when a set of these restrictions sits in the middle, it’s really hard for models to optimize across all of them, and at least my contention is that there is no way models will be able to answer these kinds of questions unless they have a grasp on their metacognitive skills, that they know they can solve certain problems. Once they have that, they’ll be able to take the next step forward in creating collectives that can solve different problems together. Until then, they’re stuck in the agent-subagent hierarchical structure.
Adam: Is that something that you could imagine being solved by another layer of RL [reinforcement learning]? After you finish off the model, you give it another opportunity to learn what it knows.
Rohit: Plausible. I feel like that should be possible. That is what we called for in the post, saying that we need to train the models to know what they’re good at. I think it would be useful for a wide variety of situations, this being one of them. But even for things like when you ask them a question, they should know the answer or know that they don’t know the answer. You want them to be able to say, “don’t know.” This used to be a big question. They’re much better at that now because we did train a lot of negative information into the models as well, among other things. The models are generally smarter.
Adam: And with certain tools, for example, it’s added a lot to those.
Rohit: Correct. We have been able to trade some of these things in. Similarly, I feel like this is another thing that we can train. The thing that makes it complicated is that knowing what you’re good at requires some sense of knowing what you’re good at across everything that you can do, and models now are microcosms of the entire world, which means knowing what you can do in everything is really hard. You might know how good you are at writing an ML [machine learning] program in Python. But do you also know how good you are at composing a new symphony or writing a haiku or a stand-up comedy joke that plays really well in New Zealand? I’m not sure.
Adam: How do you see this evolving? I know you looked a lot at hierarchical versus markets, for example. The markets have certain issues because of this lack of self-knowledge. If we assume that maybe that improves a little bit over time, my high-level read of your work suggests that the market-based approach is significantly more promising due to information asymmetries, for one thing. What does it look like in six months’ time to have a set of agents effectively doing something? What is the number-one startup doing, because they’ve been reading Strange Loop Canon, differently to the others, in order to help manage these problems that we’ve been talking about, whether it’s fraud, information asymmetries, principal-agent type problems, this question of models that rigorously follow explicit rules but then end up missing what we might think of as implicit rules? What does the state of the art look like in terms of dealing with this kind of thing?
Rohit: There are two sets of questions here. The first set is: considering the benefits and drawbacks of the current models, or some version of the current frontier models, what does the state of the art look like if you want to combine them together to solve harder problems? Part of it to me looks like you’re going along the slope of progress, maybe a little bit of a curve here or whatever. But if you draw the straight line forward, in order for us to hit the next major leaps, the startups will be able to get the next or next-to-next generation models’ capability by making the current generation models work with each other. That’s one way I would think about it.
You would see a blow-up in their ability to do longer or more complex open-ended tasks over time, for example. I am reasonably confident you’re more likely to see this in non-coding domains because, with coding, you can verify the rewards. That effectively means for a lot of coding-type problems, there is such enormous pressure being put in the normal direction that you presumably don’t need extra effort that actually benefits it. I’m not sure about this, but that’s my hypothesis.
But everything from research, to reports, to analytics workflows like the one that I did for dinosaurs, or any of those kinds of questions: you’re going to see far better harnesses that enable the models to play nicer with each other to develop the types of outputs that you want. You can put in a fair amount of institutional guardrails to solve for some of these things. It’s very hacky, but I feel it’s possible. If you train that into the models, you can start having the models behave in a somewhat appropriate fashion.
You can start seeing, it’s not quite an autonomous organization, but it’s like an autonomous department where you can still look at the outputs that are coming. Yes, you do need to look at it and go, ‘no, no, you missed it’, or ‘you did some fraud even if you didn’t intend to’, and have them feed back. I know some labs or people are working on things like, can we just create an oversight agent that looks over what everybody does and gives it back. There are problems with that approach as well, which doesn’t scale, et cetera. But this would be a concrete way to think about the capabilities that might emerge.
The second thing implicit in the question is: in order for the truly out-of-bounds thing to happen, what would a market enable you to do?
Here I am relatively confident that if we do crack the markets approach, the decentralized approach, if you will, you’re going to be able to see long-running, self-coordinating swarms, for lack of a better word, of agents working together on some problems. I don’t know exactly what sort of problems would make most sense for them to do, but we know that there are companies out there trying to solve open-endedness research. The question is not just, can you solve X benchmark, but can you work on a problem autonomously over a period of time? For you to do something like that, you need multiple agents to play nice with each other, because there is no other way you’re going to do the handoffs and slowly climb the ladder of abstraction.
Because the way any kind of open-ended problem has been solved, at least in the past, is an enormous number of failures: you fall into pitfalls, come back out, learn something, and go to something else. You might try something in a completely different area and then some insights from that might flow back into you. That weird, non-directed loop, unclear to outsiders how it would happen, is effectively what you want multiple agents to be able to work together and solve.
They need to be able to coordinate with each other with, well, you can’t just coordinate with Markdown files, is at least my contention, because over a period of time it pretty quickly adds up. Each of the models is pretty quickly giving the others a Proust-sized dictionary to read before they can actually onboard, and that’s not going to work. You need it to be sharper. They will probably need some kind of mechanism or coordination way to exchange with each other. Money, a money equivalent, something like that so they can bid, ask, choose certain tasks when it works. It’s great. Otherwise they work on task decomposition with each other. Anyway, there’s a set of ways in which they have worked. Sorry.
Hayek and Local Knowledge
Adam: This is a Hayek-type critique in some ways, right?
Rohit: I think one of my longstanding critiques against this AGI/ASI [Artificial General Intelligence / Artificial Superintelligence] worry has effectively been a Hayekian critique, which is that you’re not going to be able to teach a model everything about everything and have it not require coordination with anybody else. Local knowledge is not something you can assume away. I don’t think you can assume it away regardless of where you apply it or how you RL [reinforcement learning] it. We can’t assume it away even today. Even in the most data-rich, RL-rich environment, which is automating AI research inside AI labs, humans are still very clearly in the loop because they have local knowledge that might be directly related to the problem, or might be a hypothesis they came up with when they read Hyperion the night before. That’s what actually moves.
Adam: Or some tacit political understanding that a particular data center has quietly been promised to some other company in part, or something like this. All kinds of knowledge that might not be made explicit.
Rohit: Correct. I know we can get X number of GPUs tomorrow, but if we played it this fashion, we can get three times that a month from now; that’s enormously valuable. Because that’s the currency with which all the different decisions actually happen at any layer of abstraction.
Adam: So that’s within a particular organization, let alone coordinating across multiple organizations, where not even theoretically is there any interest in proper information-sharing. There needs to be something that could nonetheless allow information in condensed fashion, and the thing that’s been most successful in that is prices.
Rohit: One of the funny things I discovered in the work so far is that model diversity really matters for answering hard questions. If a model fails in the market, for example, you take it out of the market and someone else bids, that actually increases the chance that you get to the right answer compared with the same model bidding on it again, even with knowledge of its prior failure, which is interesting when you think about it. Like you have 3.1 Pro. I tested it with maybe 5.2, I forget at this point…
Adam: So this is GPT versus Claude versus Gemini.
Rohit: Claude versus Gemini. If one gets something wrong, it’s actually somewhat better to get someone else to take a crack at it and come back, as opposed to you taking a crack at it again. I don’t know exactly why this might be the reason, but if you’re the user, quite often it is much nicer to swap between models as opposed to being a model maximalist. And if you are building Codex…
Adam: Do you think spikiness of the models would be something that comes into play here?
Rohit: It’s something to do with spikiness, something to do with maybe they get into weird basins. When you answer something and get it wrong, maybe you find it difficult to come out of some weird corner of the high-dimensional landscape. I don’t know exactly what the logic might be, but it’s clear. In fact, it was very clear when I did the market work that model diversity really helps answer difficult questions. Once you see that, you’re like, okay. Regardless of how similar these models are in some ways, and they are very similar, it is still useful to increase the diversity. If you believe that the models will keep getting less similar over time, which is a reasonable hypothesis, then you should be able to see model diversity be super important for solving problems in the real world working together. Three superintelligences working with each other is probably better than one mega-superintelligence that knows everything.
Adam: Why would you suggest that they, this is something of an aside, but why would you suggest that they get less similar over time?
Rohit: The hypothesis here is that they don’t share much with each other anymore.
Adam: They’re distilling each other’s outputs and so on.
Rohit: The hypothesis here is that even if you distill each other’s output, you learn much less from each other than from the secret sauce that you have in actually training them.
Adam: I see. So it’s only DeepSeek that is really publishing the architecture and so on anymore.
Rohit: Their full stack… I actually don’t know if even DeepSeek is publishing deep internals about how they’re dealing with their data and synthetic data creation architecture. I know they are technically, but I don’t know whether they have published all of the data sets that go along with that. So in some ways, I still find it really weird that you ask Claude, GPT, Grok, DeepSeek most of the normal questions and you get extraordinarily similar answers. They’re all fairly normie, economist, kind of liberal answers to a wide variety of questions. Occasionally, yes, there’s a spike in. If you ask Grok about Republicans in the US or DeepSeek about Tiananmen or something, you get some weirdness, post-trained weirdness, but the models are more similar than they are different in those regards.
Adam: Well, this is why I ask the question. I mean, it’s not maybe...
Rohit: But I think it’s an artifact of history, right? Now that they’ve all locked down and everybody’s in on synthetic data internally, there might still be convergent evolution because they’re going after solving the same kinds of problems. But I feel like they’re not publishing their research, they’re not publishing their data, they’re having more and more stringent NDA-type [Non-Disclosure Agreements] rules such that you can’t really leak stuff to each other. So hypothetically they should start getting less similar. If they don’t, that teaches us something as well. But even as things are, model diversity helps, which is interesting.
Adam: It’d be useful if that continued, I guess, is your point.
Rohit: Correct. For us as users, it’s wonderful. You’re not living in a world dominated by one archetype over another.
Adam: I guess this is getting quite far away from what we’re talking about. But even just from a liberalism in general approach, having multiple models that could give answers so there is not a single source of truth.
Rohit: I’m hopeful. I believe in a pantheon of the future as opposed to a unitary God, for lack of a better word. I’ve always thought that is more likely because it is really hard to beat Hayek. The technological singularity you have to imagine to go beyond that is so insanely powerful, with no levels of scarcity, that once you imagine it, it’s almost like, what’s the point? You can imagine anything else at that point, right?
Adam: Even if you had a single moment in time of omniscience about every fact in the universe, or in the globe anyway—leaving aside whether the universe is deterministic for another podcast—if you had perfect information about everybody’s interests and desires and the current position of a swallow in the South of Vietnam, even that is not sufficient to understand everything about how people would behave. Because agents, anybody taking action in the world, are responding to that gestalt, even that is not sufficient to be able to understand how people would behave, because it’s only when I interact with everything else out there that information becomes available [it cannot be determined a priori].
Rohit: Think about it this way. If somebody knew everything about you at time T, whatever it might be, would they, in your past, accurately be able to predict or reflect everything that you’re interested in today to a sufficiently strong degree? Unclear. I doubt it, because for me the number of things that I’ve changed my mind on is quite high. Things that I liked that I didn’t like, or didn’t like that I liked, have changed quite a lot over time. You might be able to get some broad things correct. I’m not fundamentally going to become some different person, but we are all co-evolving with that gestalt.
The demandscape that exists all around us, that provides the different things that come our way, has over time changed the very things that we demand. And not just us: my kids demand entirely different things, and their kids will demand even more different things. Very quickly, you’re in a divergent scenario where the equilibrium gets blown up. Even if you could predict everything about you five seconds in advance, that does not give you sufficient information or ability to predict what you would want 10 years in advance, much less 50 years for humanity in advance.
Adam: I’m just trying to make this a little bit more concrete for those who aren’t familiar with Hayek. If the model, or I, know that I like chocolate and I buy chocolate at the supermarket every two weeks or something, but then I go along to the supermarket and see the price has maybe doubled because there’s a cocoa shortage or everybody’s wanting chocolate at the moment for whatever reason. It’s not until that moment that I’m in a position to actually know whether I want chocolate. And I guess by analogy, or actually in effect the same thing, when we think about you as a user of an agentic model, it’s not until maybe you would understand what the token cost or the likely output of this query of yours is, or the sorts of responses that the agent is pulling back to you, that you’re in a position to actually exercise this sort of vaunted taste. The taste is not some universal variable that some people have or some people don’t, but rather is contextual within the interaction with the agent itself.
Rohit: That is absolutely fair. It’s sort of a modern repudiation of Platonism [i.e. the idea that abstract forms or ideals exist independently of particular situations].
Adam: It’s essentially an impossible problem to solve, even with a superhuman intelligence, because it is entirely contextual.
Rohit: Correct. You’re inferring or assuming a large amount of things that are simply inexplicable in some ways for you to make real. We can assume anything we like, but you’re absolutely right. I reject the platonic ideal that this is feasible, that there is this perfect exception that you can predict on the basis of. Reality is messy. We want different things. The things that we want are contingent on what we see, what we get, or what you get. There are enough loops in there that it becomes complex.
Even in the sense of me using the model to get an output—sometimes I might know beforehand exactly what I want, more or less. But quite often, for the vast majority of cases, you’re using the model as a conduit to get to an answer, as opposed to asking a question, getting an answer and walking away. There are certain types of jobs or tasks that you can assume away from the model, because you say, hey, guess what? These jobs are just going to go away. Because we know how to replace X with Y, X being a human doing X kind of job, Y being an AI coming in and doing that job. That works for a subset of jobs or a small portion.
Adam: And would that be something like the verifiable domains as we talked about, but also tasks that are rigorously defined in scope as well, and bounded?
Rohit: And bounded. Customer service might be a great example where you might not be able to understand whether an individual query is successful, but every call center has been able to create a dashboard over a period of time where you can manage them like machines. Could you replace that with machines? Plausible, not entirely, but at least plausible to some extent. It would be better than the IVR [interactive voice response] hell that we have today. So I’m all for it.
However, that’s not the majority of human occupation or human want and rewards, right? We work whatever, 35 hours a week or whatever the number is. If you go two or three generations before, the number of hours people worked every week was much higher.
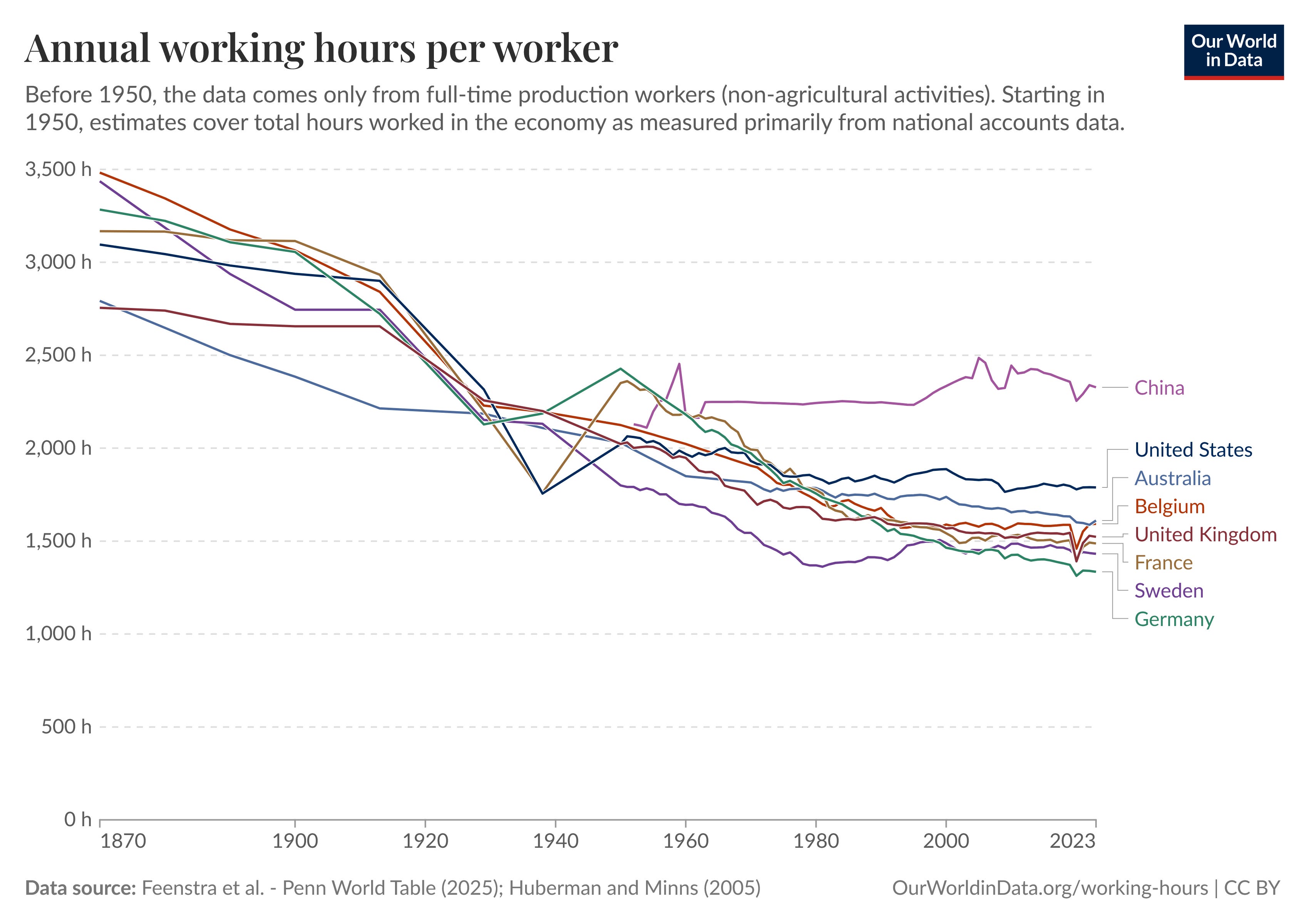
We substitute the extra time for something else that we might want to do, whether that’s child-rearing, spending time outside, traveling or whatever it might be. Our needs evolve over time.
The less philosophical way to answer the question is that engagement with the models in order to get them to do different types of tasks is how we discover what types of tasks it can plausibly do that we might actually want. Some of it might be economically valuable, some of it not, maybe personally valuable, spiritually valuable, whatever. But that process of co-discovery is not really something that can be replaced. The Hayekian principle here is something like the idea that things I want, things I know how to do, things I know how I want done, are some version of local knowledge that doesn’t intrinsically get encoded into a model just because the model has learned the sum total of patterns that has been fed into it.
Bureaucracy and the State
Adam: We’ve talked a lot about how individuals might be thinking about and interacting with these types of agents. But I’m interested to hear your thoughts on how bureaucracies and systems need to evolve in order to deal with these agents. I don’t feel like I grasp what kinds of controls you might need in order to manage multiple agents executing on some things. What kinds of governance do we need? We talked about the difference between a heirarchical structure versus a market structure. Is that a trivial slider that an individual can change? Or is there something more fundamental that needs to change about the systems now that we have these tools?
Rohit: It’s a great question. It’s a complex question. Maybe let me think about this…. I have this meta-principle. Let’s start with that. Generally speaking, our ability to deal with the systems around us lives at the edge of our ability to understand those systems. It’s almost an equilibrium conversation: today we can look back and understand fairly well how a medieval canton operated, because it’s not that complex and we can understand all the ins and outs. But if you lived in one of those medieval cantons, you probably had much less idea of how it operated.
Even if you were one of the leaders in that space, you wouldn’t, because the information flow was simply not that sophisticated. Your ability to analyze and process that information was not that sophisticated. If you use that same principle for today, or the post-agentic future working with bureaucracy, I expect our ability to deal with and understand bureaucracy is going to explode. It already explodes, right? Anytime you want to deal with a lawyer or a tax matter or some interaction with the government, the models are phenomenal because understand enough that you should absolutely use them as the first port of call for any question you have here.
Adam: All that stuff’s really well documented, like the tax code, the process that one needs to follow…
Rohit: Yeah. Otherwise you might have had to go ask an expensive professional, which is obviously a high bar. That bar has just been lowered to 20 bucks a month. You should absolutely do it.
However, the flip side is that now we have created overhead for the bureaucracies themselves to get far more complex than they were otherwise. I see no logical reason why they wouldn’t. Just because we’ve been given the ability to have this magic mirror that looks into something and understands the soul, or you are able to ask questions of it, the same thing applies for bureaucracies. We live under governments that have constantly lived under this barrage of extreme amounts of data flying in from all sorts of places, and they have the almost impossible task of making sense of some pieces of this data to identify what they should or should not do. I mean that in the more limited technocratic sense, as opposed to the political sense of what can you do, what are you allowed to do, what do you have interest in, and so on. So you push this to the...
Adam: But for example, the condition of a particular piece of infrastructure. There’s some rust there and that’s one piece of information out of 18 million data points. But if you run an AI over it, maybe it understands that given that piece of structure, that’s something that should be treated with alacrity. Just as example of something you’re talking about.
Rohit: Correct, but now you need to go from “I have identified one problem” to “Do I need to solve a bunch of these problems?” In order to do that, bureaucracies have also 10x’d their ability to go off and get things done, if they wanted to. Whether they want to or not is a much more complex question, but could they? For sure.
They have the ability now, or at least they’re starting to have the ability to do it, and the best place to see that is perhaps something like the military, where they do want to do some of this stuff. Suddenly you’re starting to see Ukraine able to withstand a much larger force because they’ve identified and used autonomous drones to defend themselves.
That completely changes the shape of how top-down bureaucratic decision-making has broken down into slightly more cell-based local autonomous decision-making with loose governance and large amounts of freedom to accomplish certain tasks. Could I see the same thing happening in the US healthcare market? I don’t know. God, I hope so. Probably not. The meta argument that bureaucracies themselves are likely to get far more complicated, so that somebody cannot easily understand them, also holds true, maybe because there will be more ways that they can do pork-barrel stuff. Right?
Today, if you want to pass some kind of law at congressional level, you have to bribe every individual involved to try and go off and do things because, oh, we’ll give you jobs in your state or whatever. In a world where all of this becomes much more explicable, you need to find more arcane ways of trying to provide that same kind of outcome that they cannot easily decipher or understand. Maybe it’s two steps removed and you play this game of chicken. The relationship here, in some senses, is that the ability of the bureaucrats to do more complex things has increased.
Some of this can be really bad. They have a large amount of information about every individual. Our expectation of privacy is effectively dead, I would imagine, at this point. At the same time, we have the ability to understand everything the state is doing. There is this detente that we are in where both sides have powered up, in the sense that the new equilibrium we are likely to reach is one where we have unprecedented ability to understand certain things the state is doing. At the same time, the bureaucracies of the world, not just the state, the companies, whatever, have unprecedented ability to execute things that they would not have been able to do before. Now there is a new kind of tension that comes up. There is a new equilibrium that we’re going to head towards. Does that make sense? At least that is my meta-principle: we level up a little bit on both sides.
Adam: Yeah. Just on that question of Ukraine and this idea of essentially increasing complexity via decentralization, would that be a broad prediction? It may not happen everywhere, especially where there’s a great political desire to see the opposite occur, but as a general rule, would you expect that, as a result of individuals having so much more ability or leverage as a result of these tools, organizations that are very mission-oriented are going to need to reorganize along those lines, where you have small teams of people able to work autonomously within broad-based guidelines? Is that a general prediction for the future of these systems?
Companies as Cities
Rohit: That is my expectation, that it is much more likely you would be able to do that than get massive centralized bureaucracies doing command-and-control hierarchies down so many levels. Partly just because you no longer need large command-and-control hierarchies: you can now have similar levels of control at the lowest levels while taking out a bunch of the middle, which effectively comes down to more autonomous units. The individual autonomous unit might just have a larger number of people, or whatever, associated with them that they can now look at and that you would not have gotten to otherwise. There’s also this general thesis that a large percentage of technology we have today pushes various things towards decentralization.
Intelligence being decentralized is one example. Similarly, if you have drones, that is warfare effectively getting decentralized in some fashion as opposed to centralized tanks rolling down the pike. If you have solar panels on every roof, that is energy getting decentralized as opposed to solely getting it from the grid. If you have 3D printers getting better everywhere, that is materials getting decentralized to some extent. There will be different central choke points when this comes up: the right filament into your 3D printer, you need to get it from somewhere, but there is this movement towards certain things becoming more decentralized. Organizational setups is one of them.
At least if you look at a bunch of the layoff, reorg conversations, including from Jack Dorsey and so on, part of the ambition there is to have player-coaches or smaller teams of people who are able to have larger ownership and execute more complex things in some ways that the firm themselves might not be able to do.
I wrote this thing a while back about why companies need to be like cities. Cities are not top-down, right? A city doesn’t have a KPI.
Adam: This is like the Jane Jacobs city we’re talking about here, right? [That is, a city understood through street-level activity, mixed uses and emergent order rather than unified top-down planning]
Rohit: Yeah. You can think of the city of San Francisco. San Francisco has a large budget and a large GDP. But the mayor is not measured on that…
Adam: As an aside, SF’s GDP is larger than New Zealand, I understand. Just the tip of the peninsula, not the Bay Area, just San Francisco.
Rohit: Yes, which is absurd. You can measure it by saying this line is going up, but that’s not how everybody measures it, right? You create some kind of balanced scorecard. At the same time, one of the things with San Francisco is it is not going to die out. Even if people move out and the city shrinks a little bit, the city doesn’t die. Whereas companies shrink and die really fast. In fact, the average turnover time for a company is much lower. In some ways, it might bring more resilience to a large number of organizations if they are able to let their individual mini-commander units have more freedom in terms of going out and doing whatever they wanted. I don’t know. It’s a far-out prediction, but I think it’s not out of the realm of possibility.
Adam: So when you say more like cities, you mean like city governments, but you’ve got loads of them and the successful ones grow and the ones that don’t either perish or learn to copy what the more successful ones are doing?
Rohit: Even more insidious than that. Cities do not perish. Jericho is still around. Baghdad’s still around, right? Cities don’t just perish and die out because a city is a platform on top of which everybody comes and builds whatever the hell they want. They have to pay the subscription revenue of taxation that is usage-based or outcome-based to the government. That system seems to work because the government, to a large extent, doesn’t tell people exactly what to do. There’s this emergent realization that maybe a coffee shop makes sense to open here, somebody opens it, and it benefits everybody such that it contributes to the city.
Which is the opposite of a command-and-control company, if you will, where you know what you want to do: go to Japan and open X office in order to sell Y products to Z people. But if you have a little bit more freedom at the bottom level, couldn’t that be cooler?
Adam: So it’s like an Alain Bertaud Order Without Design kind of thinking.
Rohit: Precisely.
Adam: Mmmm. I get the point. I just wonder, thinking back to some of the examples you gave around decentralization, whether that’s something of a just-so story. I can see the benefits of doing that in a host of domains, but it seems, coming from the other side of the world in a different sector of the economy, that the opposite is often true as well: that there’s a great push across particularly public bureaucracies to continue to centralize. We’re seeing that here in New Zealand, we see that in the UK. The US has a little bit more control and historical path dependence around states being this sacrosanct thing [which enshrine a certain degree of decentralisation]. But you might say the size and scale of bureaucracies, their degree of centralization, is a function of their ability to coordinate, and these new tools are going to enable coordination at a far greater scale, and thus we expect them to grow. But I guess time will tell.
Rohit: It’s a plausible story as well. Let me be clear: I’m not saying that the existence of AI is suddenly going to bring down big government or something like that. I don’t think that’s the argument. The argument to me is slightly different. The first thing I said is we’ll create a new equilibrium where individuals have more power to understand what the state or bureaucracy is doing, and the state becomes more inscrutable in some ways. Part of becoming inscrutable is becoming larger and being able to do more stuff. A state that does 10X more stuff is already inscrutable. Nobody here who has strong opinions about the US state actually understands all the things that the US state does.
When they did all of the cuts at USAID [the United States Agency for International Development], which is an admittedly tiny part of the US state, they still didn’t know what all it did before they cut it because it is way too complicated at this point. So I see no reason why that stuff would not continue to get even more complex.
The argument about increased decentralization is different. Yes, the state might be able to accomplish more and get bigger by subsuming some parts of the quasi-state and bringing that into its own umbrella, plausible. Maybe they even become more effective. We surely will exist in a place where every state will have information about all of its citizens, which is, depending on your point of view, fairly totalitarian in some ways.
But the point being that despite that, the amount of power that the people will have in instances to understand what the state is doing creates a weird new form of check and balance that none of us are used to but presumably will become the norm in the next 10-20 years.
Adam: Right, and I can certainly buy the evolutionary argument, coming back to Ukraine, that the changes that occurred there, with these little drone teams and a far more decentralized type of army than they had going into it, were under severe evolutionary pressure to change or fail otherwise. One thing modern states tend to lack is that same kind of pressure.
So I can certainly buy that the likes of Amazon, Google, whoever, startups in Silicon Valley are going to shift more towards that type of model, and that really successful states will do the same. I hope that… I think we need to be delivering more, and there are certain ways in which states have become a little sclerotic in terms of their ability to deliver. We’ll see how it turns out…
Rohit: I’m hopeful, but I’m not holding my breath.
Agent-Native Interfaces
Adam: One thing that comes up a little in your work is that we’ve got these agents, but everything they interact with is still pre-agentic in effect, whether that’s websites, enterprise interfaces, or the UI [user interface] itself. It’s often some kind of IDE [an interface built for coding], some pre-agentic, pre-AI interface that then has an add-on. How do you see that all changing? Beyond the individual elements of the user interface changing here or there, are there new capabilities that you would expect to begin to see as a result of that?
[Transcript Text - external link check: LexisNexis, Stripe, Vercel]
Rohit: My default answer is yes, even though I’m not entirely sure if I know enough to imagine what they might be. One perhaps useful way to think about it is that every individual facet of interaction that we do via agents online is liable to change. Where does your agent do its compute? Where can it actually access all of the data that it has access to? Can it do OAuth [a standard for authorizing access between online services] and connect to your Microsoft systems or Google systems? Can it touch your CRM [customer relationship management system]? Can it touch the wider internet? Can it pay for something at LexisNexis [a legal knowledgebase] and pull it? Whatever.
All of these are weird ways that we have siloed the world, and the agents need to learn to navigate that siloed world. Some of it might just be that we have to teach the agents to surf the web like a human, because sometimes it is easier for the agent to do that because nobody’s going to give you the right APIs or CLI [i.e. direct and disintermediated] access to do it. There is a set of things that just needs to be built, which is pretty much the entire SaaS [software as a service] stack, bottom-up, that needs to become somewhat agent-friendly. Some of it is easy, some of it is less easy.
Stripe has started doing it for shopping and a bunch of other things where you can do it as well. It allows the agent to autonomously spin up a container [an isolated software environment], install whatever it wants on it, run it, blah blah. There’s a set of things that they’re trying to do. I see no reason why some version of that will not be successful in five years, in the sense of widely deployed and people using it regularly. Is every single one of my ephemeral queries going to result in a large infrastructure stack somewhere spinning up? Possible, because it does that to some extent today. If I do a freemium version of a SaaS application, that’s how it’s happening, right? So the same principle could happen somewhere in the middle.
Now, in order to get to that future, you would have to get to several stage gates. Yes, you need to rebuild all of these. The agents themselves need to get better at handing off from one agent to the other rather than one guy saying, I will just do everything. You need to be able to talk to the Stripe agent, negotiate something, come back, do the thing on your own, and then go on. It’s the same thing for Vercel, whatever… I’m just using coding examples…
If you want to do trip planning, the classic example that everybody uses, you want it to go off and find a bunch of places, check, come back, realize, negotiate with somebody on WhatsApp, and then move on to email for someone else. There’s a weird form of coordination, self-coordination, and coordination with other agents that it needs to be able to do. I absolutely hope to see that solved.
Adam: Hand off to a lower-cost agent to process some text or whatever and generate some kind of summary.
Rohit: There will be multiple agents doing always-on scans. Some are doing routine scans. Some of the smartest ones might be doing check-ins once in a while. You can imagine this entire ecosystem working together to get you the outcome that you actually want at the ultimate end of the day. What is the new thing that will emerge from it? Unclear. I think if we knew, in some ways it wouldn’t be that new anymore. I sometimes think about those old movies where they thought about surfing the internet as flying through large cabinets put in some places. They weren’t right, but they were trying.
Adam: “It’s a Linux system!” The classic line from Jurassic Park where it’s like zooming through space…
Rohit: That’s what I’m saying. You imagine these things and you’re like, that’s not how things turned out, right? Instead, we have the ability to have supercomputers in our pockets and we can post memes from them all day, which people do. Things evolve super weirdly. So I’m bearish on the ability to accurately forecast, but bullish on the ability to say some things will definitely happen.
StarCraft and Agentic Skills
Adam: You’ve talked a little bit about the agentic user as being something like a player of StarCraft: Brood War or some kind of strategy game. You’re multitasking, juggling context, building your base or your infrastructure, dealing with some adversarial issue over here, verifying that the agent or the SCV [a worker unit] that you’ve told to do this has actually done it in a satisfactory manner.
I think this was quite interesting to think about. It seems like we’re a ways off the UI or not just the UI, but the very nature of the interaction itself actually facilitating that. It’s still very much based on prompts.
Rohit: We are still in the very early innings of this. I feel like people have started to build this in some ways by being able to spin up a bunch of agents, and sometimes they bump into each other and sometimes not so much. But we are very much in the early stages. I don’t think there are many people who say they run 10 agents at the same time on the same repo or whatever. I haven’t met that many who are successfully doing it for any significant thing or period of time. Because how do you know what you want to do?
Adam: You just can’t have the mental capacity to manage that kind of thing.
Rohit: It’s a hard thing to do, right? In some ways, the transition from coder as an IC [individual contributor], to coder as a manager, to coder as an engineering lead or the CTO is a task being forced upon many people. But as you go up, you realize the sheer importance of coordinating so many other things before you are able to just do your damn job.
I think in some ways we are playing a very shitty form of StarCraft at this point. It just happens that your interaction happens via Slack and WhatsApp and email, as opposed to all being in some interface. Do I expect everything to be in a beautiful interface eventually? I don’t know. This is one that I like to imagine. I like it being a North Star that we guide towards. I can also imagine that the world remains pretty heterogeneous.
The job is still very much that of a StarCraft player in some sense, but your ability to do that is not as easy as playing the game, because the cool thing about games is that the entire complexity is subsumed into one screen. The game never says, at this point you need to go read a book and come back, or go talk to five people and come back. Everything you need to know is in that screen, which is an incredible amount of information compression into one screen that I feel real life is never going to get to. But I like it as a goal.
Adam: Thinking outside the UI, but extending the StarCraft analogy for a little bit, Brood War was, what, 1998, and then took off in Korea. This is going somewhere, by the way, for non-StarCraft nerds. It absolutely blew up in Korea. I think some of the first televised matches were around 2001. There were players in these futuristic booths while they were playing. But even as recently as 2005 or 2008, this game was 10 years old. If you compare the very best players in the world then, in 2008, to a mid-rank ladder player today, the mid-rank player today is so much better than the one even after 10 years.
And so we were praising humanity before about being adaptable and not getting too attracted to these basins. There is obviously extraordinary evolutionary pressure for people to get better because their livelihoods depended on it and a lot of status. Yet it took, let’s say, 15 years before something approaching modern gameplay really emerged. I can imagine something similar happening with agents, given what we’ve talked about, with massively more complexity.
So even if capabilities paused today, you could still imagine it might take 20 or 30 years for an individual, let alone systems of people and bureaucracies, at age 20, just getting into agentic engineering, to really begin to adapt to the tools and adapt their thinking, their ways of working, and the sorts of things that they’re working on. The things we think are important to focus on now might actually be trivial irrelevancies, some little minor micro-optimization, and the real important thing is building your infrastructure properly, who knows? I think we can only really begin to grasp at what might be important.
Rohit: I think we get to that point by doing it. We won’t know exactly what that looks like. There are already people who are entirely AI-native or agent-native starting to come into the workforce, and their way of approaching problems is quite alien to people who did things before.
That’s not going to stop at any point soon. The more you use it, the more adept you are at using it, even things like identifying when the model is going wrong, asking it to do different things, or asking it to do a hundred things, then choosing two of them from the mess the right way. There are a variety of ways in which people use these models that are not easily understandable to most people who are not playing with it every day, and I expect an incredible change in how this is likely to happen in the real world.
Adam: And there’s also relatively little cross-pollination of those ideas, particularly outside of San Francisco, right? Somebody in Wellington or Singapore is doing something and no meta [i.e. a broad understanding of how best to play] is really emerging yet.
Rohit: I don’t know, man. I feel like San Francisco is definitely a bubble, but I keep going back to this: Anthropic is at whatever, $45 billion ARR or something, every large company basically says they’re using it or playing around with it in some way, shape, or form. Most of the pieces of documents that I see created around the world are somewhat AI-written. Pangram [an AI-text detection tool] is basically flagging everything as AI. ChatGPT has a billion weekly active users or something. I feel like we are not in the early innings anymore.
People might not know how to use it well, but people do know it exists. They’re maybe touching it or playing with it or slightly scared or whatever. There are a variety of ways in which they are, but I think we have passed the Rubicon in some ways.
Adam: No disagreement there. I guess I was only just speculating that the sort of meta that we might see emerge within, let’s say, five years’ time where, you know, you prompt the models in this way when you’re doing this kind of task and you learn, you know, set these kinds of parameters over here, these kinds of things which will become standard, I imagine, or may not, but we’ll see.
But it’s all still incredibly distributed across the organization. Sorry, across the world, as individuals figure out what works for them and there hasn’t necessarily been a lot of cross-pollination.
Rohit: I think that’s the thing. People need to figure it out for themselves in some ways. We went through a phase of prompting being super important. Then we went to a phase of maybe it’s not that important. Now we are in the phase of it being really important insofar as you’re able to explicitly articulate what it is that you actually want, which is the hardest thing in the world. In some ways, yes, true, but is that sufficient? Unclear.
Local Prompting and Professional Expertise
Rohit: So I feel like we have gone around in a roundabout fashion to getting to a really hard problem. I think that exists everywhere. It’s not like if you’re a lawyer in New Zealand, you fundamentally need to prompt it the same as the lawyer in San Francisco and just learn from the same prompts or whatever. No, you need to imbue it with your experience and expertise and types of questions you get asked, et cetera. This too will change.
Adam: Playing different language games almost, in a way.
Rohit: Maybe it’s a different language game. Maybe your clients are subtly different. Maybe the things that you’re used to are subtly different. There might be a dozen things, none of which I know of, that mean if you’re a lawyer in Wellington, New Zealand, you might need to ask certain things differently than if you’re a lawyer in San Francisco. Maybe not. Maybe some of it is very simple and straightforward and the model just gets it. You say I’m in New Zealand and it assumes everything else. That’s also possible.
But also five years from now, when new people are setting up their practices in both of these places, how much of their profession is going to resemble what a lawyer did two years ago? I don’t know. Very little, I hope, because a lot of it is rote work that should not exist, right?
Adam: We talked last year with Anish Tondwalkar about the idea that where most junior staff members cut their teeth is in the rote work, and that’s being automated away or that’s no longer necessary. Go look up the statute, or this case study, or whatever it is. That gives them the exposure to an organization and the implicit rules of advice that you might give to a client: here’s what the law says, but here’s my risk assessment, which is where a lot of the value really sits. They pick that up through years of being in the meetings and having read through the case studies themselves. It’s not yet clear how that looks in five or 10 years’ time, as you get this generational change. Anish was very optimistic about it: you just have these decentralized things, people get to the meat of the issue quicker, and they actually end up better lawyers than they were.
Rohit: I believe they will be better lawyers as well. I just think what a better lawyer means will change quite a lot. The TV show ‘Suits’ had the dude who could remember everything that he read, something like that. Is that important to be a great lawyer? Maybe then, but now?
Adam: It’s a common trope for medical and detective dramas and so on.
Rohit: Is that really the limiting constraint today? I don’t think so. We went through a property legal thing in the UK recently, and I feel the biggest benefit the lawyer brought was different. He did some of this and most of this was useless because we could get the exact same or better information from GPT, and we did and would send it to him. The biggest benefit he would provide was to say something to the order of, yes, those four are the right options or these are the things that we can do.
But this has a higher chance of working in my experience, or based on X, Y and Z here, we have seen this work more. Those are things you need a large amount of real-world information before you can say, right? GPT’s legal analysis is great and it’ll probably get better, but this practical knowledge is not really embedded into GPT as much. This is a relatively realistic example.
Adam: So the efficient market hypothesis kind of thing again, right?
Rohit: Correct. There is some level of localized knowledge that doesn’t exist in the model that if you are a professional in the field or doing it a lot more, you will be able to get better at. So as long as the profession exists, they will be able to do different things than what they do today. Because I don’t need you to write a four-paragraph email outlining the six options. That’s done. We don’t need that anymore. Don’t spend two hours doing that. But do you want to do more calls explaining some of these things, where they’re coming from, where you’re coming from and how this actually evolves? Yeah, that’s probably more useful now than before. It’s just a change. There’s no information arbitrage anymore. It’s, rather...
Adam: So it’s almost like it’s probably as important as it ever has been. Maybe this is an optimistic framing, but we’re able to move up the stack a little bit more and towards the higher-value outputs, right?
Rohit: It’s a local knowledge arbitrage. Correct. Every lawyer is now a senior lawyer. That’s the way I would put it. Everyone now has to focus on the exceptions and client service and what happened before and giving better advice, not just being proficient in the act of digging up case studies.
Adam: How does someone get trained into that space though? Like a lawyer, I mean, like a software engineer, for example, you might go, ah well, I’m just going to publish my own stuff and if people like that, then I can build up a portfolio that maybe gets me hired. But if you’re talking about every lawyer being a senior lawyer or every engineer being a senior engineer, how does someone in that space get their first gig and get runs on the board?
Rohit: The first gig gets more complex, right? The first gig itself gets more complicated. That’s all. It’s not like, just because the current first-year associate’s task can be done by GPT and everybody needs to act like third-year associates, that you only hire third-year associates. It just means that the first-year associates you hire next year have to be as good as third-year associates. If you assume whatever fallow period goes away, that’s true of everything. Investment banking analysts hired today are probably better than vice presidents that existed in the 90s, because they know more and do more. This is true everywhere.
Adam: But you still need some kind of credibility signaling, like an actual genuine principal or somebody that has a reputation that can be traded on.
Rohit: Over a period of time. But it’s the same thing, right? It’s the same profession in some ways. It’s just that the entire stack is getting up-skilled. That’s all. It’s not like the profession is going away. You’re getting up-skilled across the board. I’ll give you one stat: when I was at McKinsey, the day-one answer that we would provide to some clients, with the pre-analysis and whatever, would be equivalent to an entire study that was done in the 90s. So what happened to all the people who did the studies? They went up. The new bar goes up, but your ability to deliver also goes up, and that continues along the trajectory so that everybody can do a little bit more. Will all of it be directly useful? Hell no, because it’s consulting or law or whatever. It’s a service game. But at the same time, the fact that it can be done doesn’t mean that suddenly we needed less consultancy. We needed more. It means we need more bankers and more lawyers.
Productivity and Decision-Making
Adam: So does all this show up in the productivity statistics within the next few years, do you think? Or do the gains accrue to sort of individuals working less? Do we get back to pre-1970 productivity growth?
Rohit: The argument is that we are already starting to see some of that productivity growth coming in. In the digital sector, I suspect, yes, we will start to see productivity growth if we have not already started to see it. In the physical world, it’s a little more complicated because the reasons that hold productivity growth back are not as simple as people are just not working or not being coordinated properly enough. But I am hopeful that we will be able to see more of that there as well. This is without assuming robots, I should say. Once you assume robots, there’s a little bit more work that you can probably do. I think it’s actually a harder problem than we give it credit for.
Actually, let me step back. The last 50 years of technological innovation to a large extent has made us really good at moving information back and forth from all corners to all other corners. What was lacking is making use of that information to do something. Suddenly, you had 10x the amount of information coming at you, but you need to do something with it. There are 17 different BI [business intelligence] trends that came and went, but it doesn’t mean your decision-making improved dramatically in any meaningful sense across the board. That’s a contentious conversation, but it hasn’t increased that much.
Now the new trend is we have far better processing capability for the information threads that are coming our way, which means hypothetically we are able to use the information coming in and make better decisions, or at the very least make decisions faster. That should have an effect. Data, yeah.
Adam: So rather than just swimming in information, instead we make it legible, make it at least theoretically actionable. And then there’s, I guess, human agency that needs to sit atop that.
Rohit: Then you are going to take some action on the basis of that, but at least you’re not swimming through 3,500 dashboards before you go off and do something. Presumably that has some kind of impact. So digital-realm productivity gains, absolutely. In the physical realm, I suspect we will start to see some just because we are able to do some things better now than we used to be able to. But the physical world is also held back by all sorts of things: regulations, consumer interests, tariffs, all sorts of things that make it harder.
Adam: Logistics. The Straits of Hormuz.
Rohit: Correct. So these things are really difficult to kind of compress down into one thing and say whether it works or not.
Adam: Great. So we’re coming to the end of the time here. Is there anything else we haven’t talked about that you wanted to cover off?
Rohit: I think we actually did a nice tour through quite a few different things. It was wonderful.
Adam: I’ve really enjoyed the chat. Look, thanks so much Rohit Krishnan for chatting with me. Go check out Strange Loop Canon. The work is absolutely fascinating, and you’ve hinted at some experimental work that you’ve yet to publish, so check that out.
Rohit: I have several coming out over the next five or six weeks that I’ve queued up. There’s a bunch of cool stuff, at least cool to me, that is definitely coming out that explores much of the conversation we had in a lot more detail. Weirdly enough, when I started doing this last year, I felt like there is some new world here where you can actually do social science experiments on agents, social science and economics experiments on agents. There’s no word for this new field and it is enormously fun. It teaches you a huge amount and it’s in its genesis. So it’s fun to play around with it. That’s why I have more ideas than even I know what to do with, or even my agents can handle at some point. It’s fun. Thank you for having me.
Adam: It’s only going to become more important as these things diffuse through the economy. Look, thanks again. Real pleasure speaking with you.
Rohit: My pleasure, Adam. This was lovely.
If you’ve enjoyed this, please consider hitting the little heart button below the post (and/or leave a comment). It doesn’t affect the algorithm, but it’s useful feedback for me about what people find interesting.